MAGI
Multimodal Audio and Gesture, Integrated
This project is maintained by shivammehta25
MAGI: Multimodal Audio and Gesture, Integrated
Shivam Mehta, Anna Deichler, Jim O’Regan, Birger Moëll,
Jonas Beskow, Gustav Eje Henter, and Simon Alexanderson
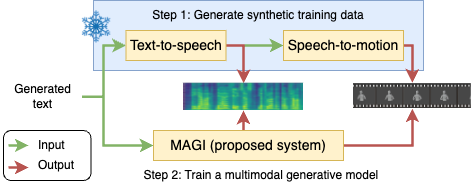
Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data.
Overview
Generated sentences
Click here to download the CSV file
Example stimuli from the evaluation
Speech-only evaluation
Click the buttons in the table to load and play the different stimuli.
Currently loaded stimulus: MAGI-FT , Sentence 1
Audio player:
Transcription:
Like every, I think most people even people who never go to mass ever will go to mass on Christmas Eve or Christmas Day. So like what we used to do is we used to go to mass on Christmas Eve which was lovely it's such a nice ceremony because it's so like it's obviously 12 o'clock at night.
| Text prompt # | NAT | MAT | MA | ||
|---|---|---|---|---|---|
| MAT-T | MAT-FT | MAGI-T | MAGI-FT | ||
| 1 |
|
|
|
|
|
| 2 |
|
|
|
|
|
| 3 |
|
|
|
|
|
| 4 |
|
|
|
|
|
Gesture-only evaluation (no audio)
Currently loaded: MAGI-FT 1
Trying to see if if we can go back to the olden ways of just talking to people and actually engaging and communicating and seeing if can relationships form with just.
| Text prompt # | NAT | MAT | MA | ||
|---|---|---|---|---|---|
| MAT-T | MAT-FT | MAGI-T | MAGI-FT | ||
| 1 |
|
|
|
|
|
| 2 |
|
|
|
|
|
| 3 |
|
|
|
|
|
| 4 |
|
|
|
|
|
Speech-and-gesture evaluation
| Matched | Mismatched |
|---|---|
*Note: Matched versus mismatched stimuli were not labelled in the study and presented in random order.
Currently loaded: MAGI-FT 1
and they finished they they cleaned up the wound and stuff I stood up and I just collapsed onto the ground and fainted because I was completely drained of all my energy of of everything like it was absolutely. Oh, so so bad.
| Text prompt # | NAT | MAT | MA | ||
|---|---|---|---|---|---|
| MAT-T | MAT-FT | MAGI-T | MAGI-FT | ||
| 1 |
|
|
|
|
|
| 2 |
|
|
|
|
|
| 3 |
|
|
|
|
|
| 4 |
|
|
|
|
|
(Videos generated using the same seed)
Currently loaded: Factor: 0 Video 1
I mean it it's not that I'm against it it's just that I just don't have the time and I just sometimes I'm not bothered and that sort of stuff.
| Text prompt # | Pitch Factor | ||
|---|---|---|---|
| -1 | 0 | +1 | |
| 1 |
|
|
|
| 2 |
|
|
|
| 3 |
|
|
|
| 4 |
|
|
|
![]()