
(Migrated from old blog)
Ever wonder? How Microsoft Word checks that the spelling that you wrote is correct or not? So there can be various language models that can be used but one of the most major implementations is Trie or Prefix Trees.
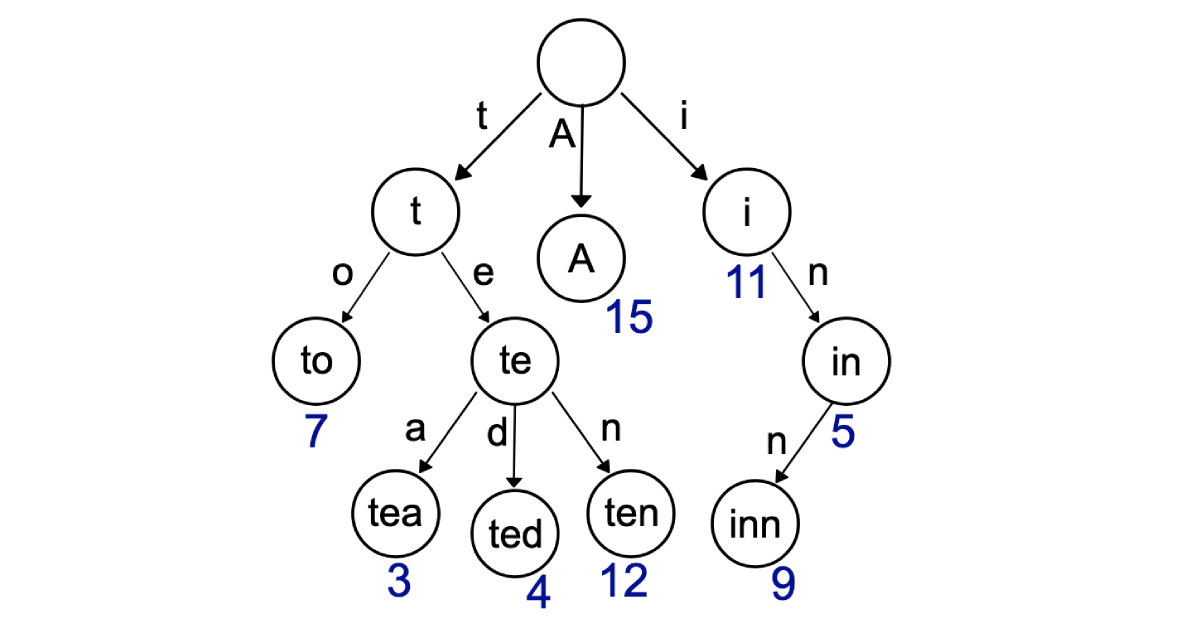
So, Trie is a treelike data structure where each node represents the next character that the tree can have. All the nodes in the Trie has common prefixes.
So how it works is that when the Trie is formed it can be said like a very simple machine learning model where it learns from the data. What I mean by that is initially we populate the Trie, we feed trie every word and with each word it populates the nodes in its structure.
This is one of the best videos that explain about Tries.
Tushar Roy: Trie
Implementation
Once you have understood the Trie lets start to implement it.
We Create a Node: I will be using this later as an inner class that is why it has underscore in the name.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class _Node:
"""
Node
This is how a trie node looks like it has a hashmap of characters
with an end indicating weather this is the end of word or not.
One additional field that I added is the frequency count just for
furthur probabilistic calculations if required.
"""
def __init__(self, end=False):
self.characters = {}
self.frequency = 0
self.end = end
So the Whole Trie class will look like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
class Trie:
"""
Trie
Trie is a treelike datastructure used to predict suggestion here is a
simple implementation of it with add and search functionality.
It has a root that is the head or the Trie and a node_count to count
total number of nodes currently in Trie
"""
class _Node:
"""
Node
This is how a trie node looks like it has a hashmap of characters
with an end indicating weather this is the end of word or not.
One additional field that I added is the frequency count just for
furthur probabilistic calculations if required.
"""
def __init__(self, end=False):
self.characters = {}
self.frequency = 0
self.end = end
def __init__(self):
self.root = self._Node()
self.node_count = 1
def add_string(self, string):
"""
Adds a string to the trie
Parameters:
string: String
"""
node = self.root
for c in string:
if c not in node.characters:
node.characters[c] = self._Node()
self.node_count += 1
node = node.characters[c]
node.frequency += 1
node.end = True
def search_word(self, string):
"""
Searches for a word in the trie
Parameters:
string: String
"""
node = self.root
for c in string:
if c not in node.characters:
return False
node = node.characters[c]
if node.end:
return True
return False
Basic Test Cases
1
2
3
4
5
6
7
8
9
10
T = Trie()
T.add_string('cat')
T.add_string('dog')
T.add_string('camel')
assert T.node_count == 10
assert T.search_word('cat')
assert T.search_word('dog')
assert T.search_word('camel')
assert not T.search_word('cab')
print('Test Passed Successfully')
Training it with More Corpora
I am using NLTK to just use any corpora from the Gutenberg package
1
2
3
import nltk
nltk.download('gutenberg')
from nltk.corpus import gutenberg
Let’s train it like Shakespeare:
1
2
3
4
5
corpora = gutenberg.raw('shakespeare-caesar.txt')
spell_checker = Trie()
for word in corpora.split():
word = word.lower()
spell_checker.add_string(word)
Testing our Shakespeare English
1
2
3
4
5
6
def check_spelling(sentence, trie=spell_checker):
"""This method checks the presence in the trie and
returns the incorrect words
"""
sentence = sentence.split()
return [(i+1, word) for i, word in enumerate(sentence) if not trie.search_word(word)]
Testing it
1
2
3
check_spelling('the julius ws dead when teh brutus stab him with the knofe')
#### Output ####
[(3, 'ws'), (6, 'teh'), (12, 'knofe')]
Time Complexity
Complexity while populating Trie
The Trie is populated in $ O(N \ast M) $ time where $ N $ is the number of words and $ M $ is the length of each word. Space Complexity: $ O(Z \ast N \ast M) $ where $ Z $ is the number of alphabets, $ N $ is the number of words and $ M $ is the length of each word.
The complexity of insert and lookup
The best part is its insert and lookup complexity of $ O(M) $ where $ M $ is the length of the word.
The Notebook can be found at my GitHub:
https://github.com/shivammehta25/Information-Retrieval/blob/master/Trie_Spell_Checker_Tutorial.ipynb