
(Migrated from old blog)
A paper by Chen Liang, Xiao Yang, Neisarg Dave, Drew Wham, Bart Pursel, C. Lee Giles from Pennsylvania State University.
Recently, I was starting with such topics in Field of NLP and a professor suggested me this paper, I found it interesting, here is a short summary on it.
Introduction
- What are distractors? For a given Question, Q = {q, a, {d1 … dk} which means for a given Question Q: q resembles the question stem, a the key or the correct answer and the set of {d1… dk} refers to the set of incorrect yet plausible answers.
- This paper evaluates how machine learning models, specifically ranking models can be used to select useful distractors for MCQs.
- They did an empirical study on feature-based models and Neural Network-based ranking models with experiments on the SciQ dataset and MCQL dataset.
Their approach?
- Finding reasonable distractors is very vital for any examination, here they generated a distractor given the stem and the key to the questions.
- They focused on cases where distractors could be more than one word
- The Goal of the Distractor Generator (DG) is to generate plausible false answers i.e. good distractors.
- They used feature descriptions (embedding similarity, Pos similarity, etc), Classifiers ( Random Forest and LambdaMART ) and NN based models.
Working
Feature-Based Models:
Feature Description
The tuple (q, a, d) is transformed to a feature vector. They design the following features for DG, resulting in 26 dimension feature vector
- Embedding Similarity of GloVe Embedding
- Jaccard similarity between a and d POST tags
- ED edit distances
- Token Similarity
- Length
- Suffix
- Frequency
- Singular/Plural
- Numerical
- Wiki Similarity
Classifiers
- Logistic Regression
- Random Forest
- LambdaMART
Neural Network Models
- Based on IR-GAN, they proposed an adversarial training framework for DG, while the original IRGAN used CNN and then calculate cosine similarities they didn’t use that as such methods ignore the word level interactions.
- Thus they used the Decomposable Attention Model (DecompAtt) which is used to calculate Natural Language Interference to measure the similarities between q and d. Also, they considered cosine similarities as well.
Cascaded Learning Framework
- To make the ranking process more effective and efficient they proposed a cascade learning method where,
- The First stage ranker is a simple model trained with part of features
- The Second stage ranker can be any of the mentioned models
- It gives an advantage as the candidate size is greatly reduced by the first stage thus more expensive features can be used by the second stage.
Experiment Settings
- They used Logistic Regression (LR) as the first stage ranker. And for the second stage, they compared LR, Random Forest (RF), LamdaMART (LM), and proposed NN-based model (NN).
- They studied similarities the key and distractors, evaluation matrices used were:
- Pointwise Mutual Information (PMI) based on co-occurrences
- Edit Distance (ED)
- GloVe embedding similarity Embedding Similarity Emb Sim.
- They used Recall, Mean average Precision, normalized discounted cumulative gain and mean reciprocal rank.
Results
First Stage Ranker
The main goal was to reduce the candidate size while achieving a relatively high recall. They set K to 2000 for SciQ and 2500 for MCQL and got a recall of about 90%.
Distractor Ranking Results
- The proposed ranking method works better than unsupervised similarity-based methods.
- Ensemble Models like RF and LM have comparable performance and are significantly better than other methods.
- NN performs worse than feature-based models, the main reason is that NN is based on word embeddings only. It doesn’t account for other features like ED, Suffix, Freq, etc.
Effects of Cascaded Learning
- Since, they choose from the top 2000 for SciQ and 2500 for MCQL the ranking candidate size was reduced by 91% and 85% respectively, which made second stage more efficient.
- To study the effect they used RF and LM without 2 stage learning and sample 100 negative samples for training models
- The Last two line in the table represents that
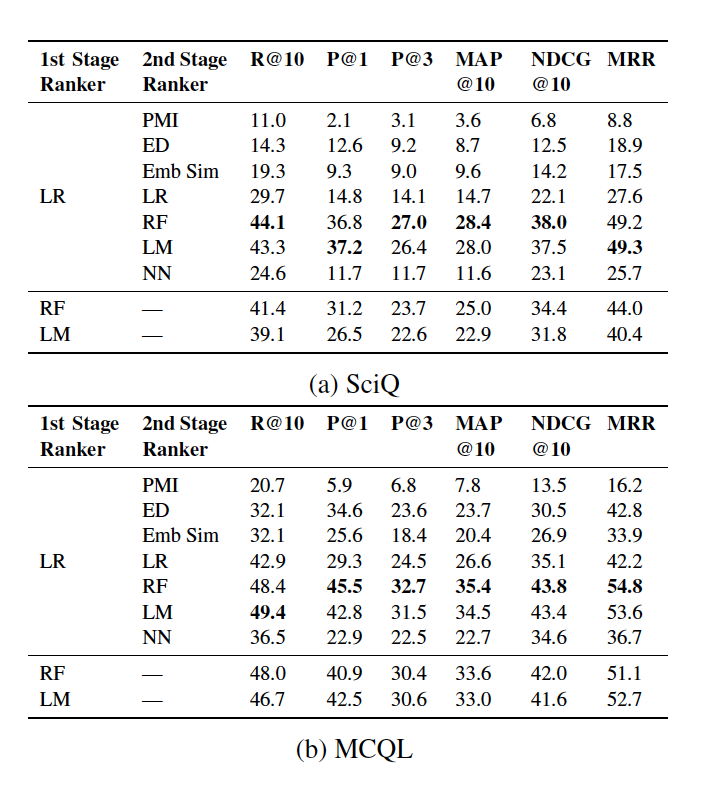 Result of the Distractor Generator Experiments
Result of the Distractor Generator Experiments
Feature Analysis
- Feature Importance was calculated by mean decrease impurity using RF
- They found that:
- Embedding similarity was the most effective at capturing semantic relations between a and d.
- String similarities like Token Sim, ED and suffix were more effective in MCQL than in SciQ.
- Top 10 features were yet the same regardless of their order in the table.
 Feature Importance for Distractor Generators
Feature Importance for Distractor Generators
Conclusion
They investigated DG as a ranking problem and applied feature-based and NN-based supervised ranking models to the task. Experiments with the SciQ and the MCQL datasets empirically showed that Ensemble learning models (random forest and LambdaMART) outperform both the NN-based method and unsupervised baselines.
More information can be found in Paper Link To Paper: https://www.aclweb.org/anthology/W18-0533/