
(Migrated from my old blog)
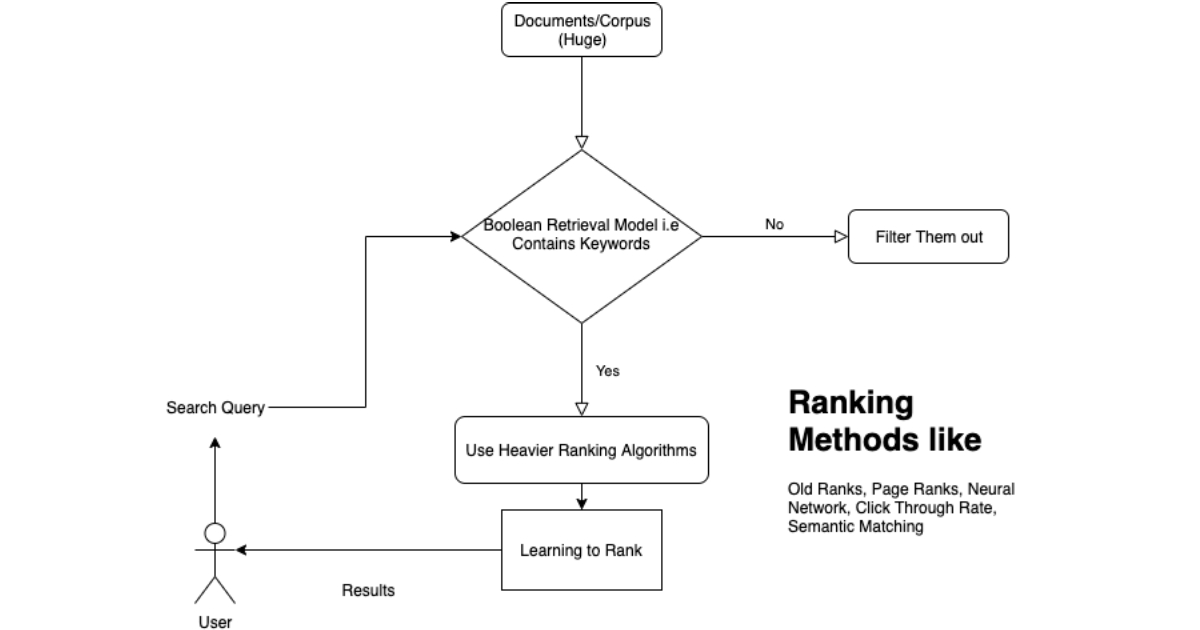
Ever wondered how google gets relevant documents for your query within milliseconds despite of such a huge amount of information it contains.
Recently, I was looking into Information Retrieval Models and other Learning to Rank models. It is then I got to know about the Inverted Index IR Model.
So Inverted Index aka Boolean Search is a common practice to determine whether a document is relevant or not, it doesn’t determine the rank of the document but rather its relevancy.
So, When you hit a search query, it does something called a Boolean Retrieval Model as its first step before actually ranking it using other algorithms.
Boolean Retrieval Model
Lets first try to understand Boolean Retrieval Model first, a very basic with just conjunctions (and operation in sets) Let’s assume we have a corpus of 3 documents
| Doc ID | Document Text |
| 1 | Dog is a very faithful animal |
| 2 | Cat is a weird animal |
| 3 | I love to eat chicken |
So we will create a Term-Document Matrix First
| Term | Doc 1 | Doc 2 | Doc 3 |
| dog | 1 | 0 | 0 |
| is | 1 | 1 | 0 |
| a | 1 | 1 | 0 |
| very | 1 | 0 | 0 |
| faithful | 1 | 0 | 0 |
| animal | 1 | 1 | 0 |
| cat | 0 | 1 | 0 |
| weird | 0 | 1 | 0 |
| I | 0 | 0 | 1 |
| love | 0 | 0 | 1 |
| to | 0 | 0 | 1 |
| eat | 0 | 0 | 1 |
| chicken | 0 | 0 | 1 |
So we have our corpus Indexed, let’s assume we search for a query
A query of ‘dog is animal’ will give me the document query like:
- dog : [1 0 0]
- &
- is : [1 1 0]
- &
- animal: [1 1 0]
So the 1 0 0 & 1 1 0 & 1 1 0 = 1 0 0
Which means that document 1 is my relevant document. Now to make it efficient other Disjunction ( OR) Operations can also be used to make it better. Let’s assume we put dog and cat be under the same category so we can use disjunction like
- ( dog : [1 0 0]
- cat : [0 1 0] )
- &
- is : [1 1 0]
- &
- animal: [1 1 0]
The query now becomes: ( 1 0 0 | 0 1 0 ) & 1 1 0 & 1 1 0 = 1 1 0
Thus, first and second documents are the relevant one’s.
Problem with Boolean Retrieval Model
- Words Can be ambiguous like: C++ is not a word
- For big corpus: $ 10^{8} $ and $ 10^{9} $ terms out of which $ 10^{6} $ unique term the Term Document Matrix will be $ 10^{8} \times 10^{6} $ which will be a lot of memory problem.
So the Solution is Inverted Index.
Inverted Index
So in Inverted Index, we will only save the relevant document id in a set for every term present in the corpus: $ \text{WORD} \rightarrow \text{set(DOCUMENT ID)} $
- $ \text{dog} \rightarrow \text{set(1)} $
- $ \text{is} \rightarrow \text{set(1,2)} $
- $ \text{a} \rightarrow \text{set(1,2)} $
- $ \text{very} \rightarrow \text{set(1)} $
- $ \text{animal} \rightarrow \text{set(1,2)} $
- $ \text{cat} \rightarrow \text{set(2)} $
- $ \text{weird} \rightarrow \text{set(2)} $
- $ \text{i} \rightarrow \text{set(3)} $
- $ \text{love} \rightarrow \text{set(3)} $
- $ \text{to} \rightarrow \text{set(3)} $
- $ \text{eat} \rightarrow \text{set(3)} $
- $ \text{chicken} \rightarrow \text{set(1)} $
The search for query: ‘dog is animal’ = (1) & (1, 2) & (1, 2) = (1) Therefore the document is available in the first one
This will be way faster.
Now Let’s try to code Inverted Index
Modules Used:
1
2
3
4
5
6
7
8
9
10
11
12
13
import nltk
import re
import pickle
import logging
import itertools
from nltk.corpus import stopwords
nltk.download("stopwords")
from string import punctuation
from collections import defaultdict
from tqdm.tqdm import tqdm
logging.basicConfig(level=logging.DEBUG)
Making Inverted Indexer Class:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
class InvertedIndexer:
"""
This class makes inverted index
"""
def __init__(self, filename=False):
self.filename = filename
self.stemmer_ru = nltk.SnowballStemmer("russian")
self.stopwords = set(stopwords.words("russian")) | set(stopwords.words("english"))
self.punctuation = punctuation # from string import punctuation
if filename:
self.inverted_index = self._build_index(self.filename)
else:
self.inverted_index = defaultdict(set)
def preprocess(self, sentence):
"""
Method to remove stop words and punctuations return tokens
"""
NONTEXT = re.compile('[^0-9 a-z#+_а-яё]')
sentence = sentence.lower()
sentence = sentence.translate(str.maketrans('', '', punctuation))
sentence = re.sub(NONTEXT,'',sentence)
# Heavy Operation Taking lot of time will move it outside
# tokens = [self.stemmer_ru.stem(word) for word in sentence.split()]
tokens = [token for token in sentence.split() if token not in self.stopwords]
return tokens
def stem_keys(self, inverted_index):
"""
Called after index is built to stem all the keys and normalize them
"""
logging.debug('Indexing Complete will not Stem keys and remap indexes')
temp_dict = defaultdict(set)
i = 0
for word in tqdm(inverted_index):
stemmed_key = self.stemmer_ru.stem(word)
temp_dict[stemmed_key].update(inverted_index[word])
inverted_index[word] = None
inverted_index = temp_dict
logging.debug('Done Stemmping Indexes')
return inverted_index
def _build_index(self, indexing_data_location):
"""
This method builds the inverted index and returns the invrted index dictionary
"""
inverted_index = defaultdict(set)
with gzip.open(indexing_data_location, "rb") as f:
for line in tqdm(f):
line = line.decode().split('\t')
file_number = line[0]
subject = line[1]
text = line[2]
line = subject + ' ' + text
for word in self.preprocess(line):
inverted_index[word].add(int(file_number))
inverted_index = self.stem_keys(inverted_index)
return inverted_index
def save(self, filename_to_save):
"""
Save method to save the inverted indexes
"""
with open(filename_to_save, mode='wb') as f:
pickle.dump(self.inverted_index, f)
def load(self, filelocation_to_load):
"""
Load method to load the inverted indexes
"""
with open(filelocation_to_load, mode='rb') as f:
self.inverted_index = pickle.load(f)
Let’s create an object for it and load the corpus
1
2
3
4
5
6
print ('Index is creating...')
start = time.time()
new_index = InvertedIndexer(indexing_data_location)
end = time.time()
print ('Index has been created and in {:.4f}s'.format(end-start))
Let’s create a class that will find documents
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class SolutionPredictor:
"""
This classes uses object of InvertedIndexer
to make boolean search
"""
def __init__(self, indexer):
"""
indexer : object of class InvertedIndexer
"""
self.indexer = indexer
def find_docs(self, query):
"""
This method provides booleaen search
query : string with text of query
Returns Python set with documents which contain query words
Will return maximum 100 docs
"""
tokens = self.indexer.preprocess(query)
tokens = [self.indexer.stemmer_ru.stem(word) for word in tokens]
docs_list = set()
for word in tokens:
if len(docs_list) > 0:
docs_list.intersection_update(self.indexer.inverted_index[word])
else:
docs_list.update(self.indexer.inverted_index[word])
return set(itertools.islice(docs_list, 100))
Creating its object and testing it
1
2
3
predictor = SolutionPredictor(new_index)
predictor.find_docs('dog is animal')
# Output: 1
Its Implementation on a Jupyter Notebook can be found on my Github: https://github.com/shivammehta25/Information-Retrieval/blob/master/Boolean_Retrieval_Model.ipynb
Some other Implementations:
- Like this Dictionary (HashMap) O(1) lookup
- Search Trees like Balanced Binary Search Trees, B-Trees etc. O(log n) lookup, ordered we can look up with prefixes too
- Sorted array, O(log n) lookup by binary search, CPU-Cache Friendly