
(Migrated from old blog)
One of the abundantly used Neural Networks for Sequential Data or Time Series Data. What do we mean when we say sequential data lets state a few examples of sequential data.
- Speech Recognition
- Machine Translation
- DNA Sequence Analysis
- Video Activity Recognition
- Sentimental Classification
But why RNN outperforms Convolutional NN or just a Deep Neural Network?
Image the task of Machine Translation, It is often that the length of input of the network lets say in a different language “Hindi” is not same as “English” in such basic cases DNN has troubles performing. Well this lets say we can solve by padding the data.
But the Bigger Trouble is that a simple Neural Network does not share the information that it learns across the different positions of texts.
Similarly, if our vocabulary is of 10,000 words (assuming representation of one hot) our first layer will have tons of neurons.
So We Understand that we need a Recurrent Neural Network for Sequential Data.
So how does a RNN looks like, In a basic form it looks something like this
 Recurrent Neural Networks
Recurrent Neural Networks
Where $ X_{\langle 1\rangle } , X_{\langle 2\rangle } \cdots X_{\langle t \rangle } $ is the input and $ Y_{\langle 1 \rangle }, Y_{\langle 2 \rangle } \cdots Y_{\langle t \rangle } $ is the output and most importantly $ a_{\langle 1\rangle }, a_{\langle 0\rangle } \cdots a_{\langle t\rangle } $ are the hidden states which remembers the historical information and do operations with the input. $ W_{ax} $ are set of parameters governing the input, $ W_{aa} $ are the set of parameters goverining the activation from one state to another and $ W_{ya} $ are the set of parameters governing the output. What are these we will discuess furthur.
But it has a disadvantage too, the sentence at $ Y_{\langle 3\rangle } $ will only get historical data from past data i.e $ X_{\langle 1\rangle }, a_{\langle 1\rangle }, X_{\langle 2\rangle }, a_{\langle 2\rangle } $ but not from the later part of series. So to overcome that we use Bi-Directional Recurrent Networks.
Let’s see how the $ a_{\langle 1\rangle } and\ \hat{y}_{\langle 1\rangle } $ is calculated
Generally the $ a_{\langle 0\rangle } $ is initialsed as zero vectors Therefore,
\[\begin{align} a_{\langle 0\rangle } &= \vec{0} \\ a_{\langle 1\rangle } &= g \left( W_{aa} a_{\langle 0\rangle } + W_{ax} X_{\langle 1\rangle } +b_a \right) \text{ (Hidden State) } \\ \hat{Y}_{\langle 1\rangle } &= g' \left( W_{ya} a_{\langle 1\rangle } + b_y \right) \text{ (Output State) } \end{align}\]Where g and g’ are activation functions mainly $ tanh $ or $ relu $
A good gif I found on the internet is
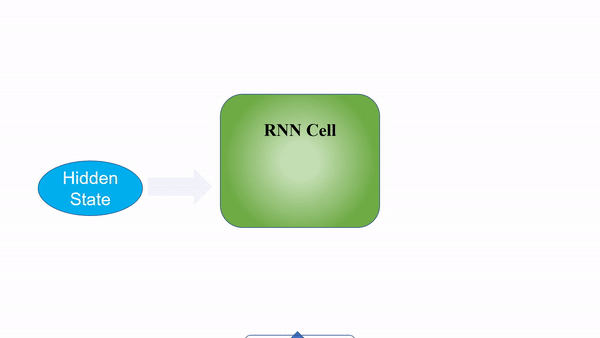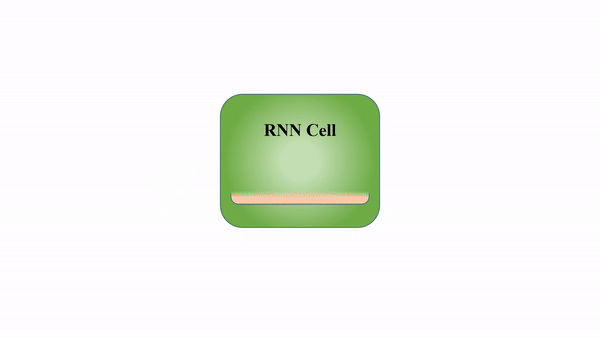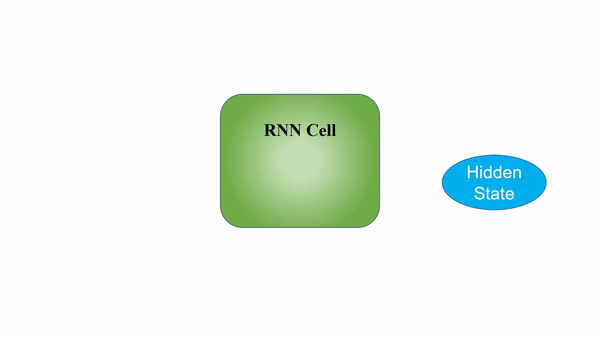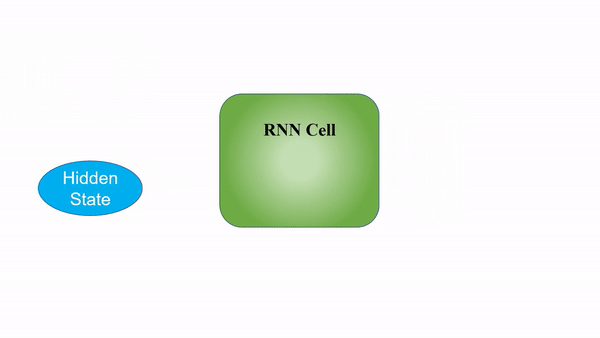
Working of RNN
After more simplification of the notation we get,
\[\begin{align} a_{\langle t\rangle } &= g \left( W_a \left[ a_{\langle t-1\rangle } , x_\langle t\rangle \right] + b_a \right) \\ \hat{Y}_{\langle t\rangle } &= g' \left( W_y a_{\langle t\rangle } + b_y \right) \\ \end{align}\]Where $ W_a $ is the matrices stacked horizontally and other braces matrix are stacked vertically.
Like most Neural Networks, RNN also falls prey of Vanishing Gradient Problems. So we use GRU and LSTM implementations of RNN.
In those we have different gates and methods to remember how much information from the past we have to remember and depending on that those gates either remembers or forgets the information.
A programming implementation of a basic RNN : https://github.com/shivammehta25/NLPResearch/blob/master/Tutorials/PyTorch_Tutorial/RNN_From_Scratch.ipynb