
(Migrated from old blog)
Okay! Its been long Since I posted something with programming today will be a programming post, lets begin, we will be generating Trump like tweets for Russia because I am in Russia and russians like to have fun hehe…
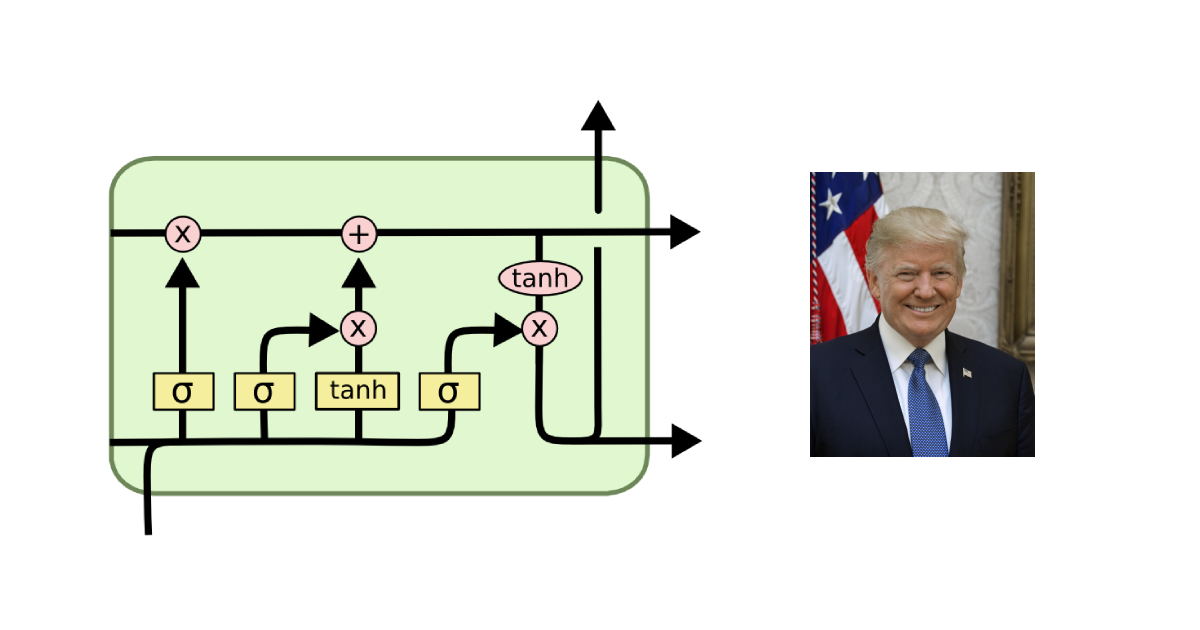
So First we should know something about LSTM a good link that I found useful is
Now LSTM is a type of GRU, which has time based backpropagation and it useful is stateful data where the previous state of data is to be used to determine the current state of data.
First Let’s import lot of important Libraries and methods. I hope you have anaconda installed because it is one of the easiest and best way to started with Machine Learning and Data Science download anaconda here .
So I coded this using jupyter-lab, I recommend you to use the same.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from __future__ import print_function
import keras
from keras.layers import Input, Embedding, LSTM, Dense, Dropout
from keras.utils import np_utils
from keras.models import Model
from keras.models import Sequential
from keras.optimizers import adam, adagrad, adadelta, rmsprop
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.callbacks import EarlyStopping
from keras.regularizers import L1L2
import matplotlib.pyplot as plt
from sklearn.model_selection import ParameterGrid, train_test_split
import os
import numpy as np
import pandas as pd
# Sometimes in Jupyter Notebook kera's give problem this fixes for me
os.environ['KMP_DUPLICATE_LIB_OK']='True'
Read the Data: The dataset I uploaded on Kernel. https://www.kaggle.com/shivammehta007/trump-tweetcsv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Read Data
folder_name = '../input'
filename = os.path.join(folder_name, 'task3_corpus.csv')
# filename = 'task3_corpus.csv'
file_type = 'csv'
def read_data(filename, file_type):
if file_type == 'csv':
data = pd.read_csv(filename)
data = data['text']
return data
df = read_data(filename, file_type)
text = '\n'.join([row for row in df])
Awesome, so now our text has all the tweets with line ending separated
As always we will follow object oriented approach creating a class with some init constructor
1
2
3
4
5
6
7
8
class ModelFormer:
def __init__(self):
self.x = []
self.y = []
self.tokenizer = Tokenizer()
self.best_model = Sequential()
self.best_accuracy = 0
self.best_parameters = {}
Lets create a method that will fit the data to our model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def fit_data(self, text):
self.original_corpus = text
self.corpus = self.original_corpus.lower().split('\n')
# Fit the tokenizer on this text
self.tokenizer.fit_on_texts(self.corpus)
self.word_count = len(self.tokenizer.word_index) + 1
input_sequences = []
for line in self.corpus:
# Convert the text to numbers
tokens = self.tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(tokens)):
n_grams_sequence = tokens[:i+1]
input_sequences.append(n_grams_sequence)
# Pad to make all the inputs of the same size method below
input_sequences = self.pad_input_sequences(input_sequences)
x_data, y_data = input_sequences[:,:-1], input_sequences[:,-1]
y_data = np_utils.to_categorical(y_data, num_classes=self.word_count)
return x_data, y_data
def pad_input_sequences(self,input_sequences):
max_sequence_length = max([len(sentence) for sentence in input_sequences])
# from kera's preprocessing sequence
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_length, padding='pre'))
return input_sequences
Now lets create a fit method that will fit and train the data to this model and will choose the best model from all the parameter grid model
First lets discuss what is parameter grid ? Suppose you have hyperparameters you can arrange them in a dictionary like this
1
2
3
4
5
hyperparameters = { 'layers': [ [( 'LSTM', 200), ('Dropout', 0.2)], [( 'LSTM', 200), ('Dropout', 0.2), ('LSTM', 400), ('Dropout', 0.2) ]],
'activation': ['tanh'],
'optimizer' : [ ('adam', 0.01 ), ('adam', 0.001 ) , ('adadelta', 1 ), ('rmsprop', 0.1 )],
'epochs' : [50]
}
Now you can run from sklearn.modelselection import ParameterGrid like this
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
combinations = list(ParameterGrid(hyperparameters))
combinations
## This will give output like =>
#####################################
# Output
#####################################
[{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2)],
'optimizer': ('adam', 0.01)},
{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2)],
'optimizer': ('adam', 0.001)},
{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2)],
'optimizer': ('adadelta', 1)},
{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2)],
'optimizer': ('rmsprop', 0.1)},
{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2), ('LSTM', 400), ('Dropout', 0.2)],
'optimizer': ('adam', 0.01)},
{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2), ('LSTM', 400), ('Dropout', 0.2)],
'optimizer': ('adam', 0.001)},
{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2), ('LSTM', 400), ('Dropout', 0.2)],
'optimizer': ('adadelta', 1)},
{'activation': 'tanh',
'epochs': 50,
'layers': [('LSTM', 200), ('Dropout', 0.2), ('LSTM', 400), ('Dropout', 0.2)],
'optimizer': ('rmsprop', 0.1)}]
So we see that it expands all the parameters into and can be used to tune the hyperparameters on the validation set.
Now writing the fit method with there hyperparameters as the value of it
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
def fit(self, x_data, y_data , layers= [( 'LSTM', 150), ('Dropout', 0.2)], activation='tanh', optimizer='adam', lr=0.001, epochs=50):
self.model = Sequential()
self.x_data = x_data
self.y_data = y_data
x_train, x_val, y_train, y_val = train_test_split(self.x_data, self.y_data)
self.model.add(Embedding(self.word_count, 10, input_length=len(x_data[0]) ))
# Count the number of LSTM layer as for the last LSTM layer before the Dense the return_sequences has to be False
count_lstm_retn_flag = [x for x,_ in layers].count('LSTM') - 1
for layer,value in layers:
if layer == 'LSTM':
if count_lstm_retn_flag:
count_lstm_retn_flag -= 1
return_sequences = True
else:
return_sequences = False
self.model.add(LSTM(value, activation=activation, return_sequences=return_sequences))
if layer == 'Dropout':
self.model.add(Dropout(value))
self.model.add(Dense(self.word_count, activation='softmax'))
# Set optimizer as per hyperparameter value
if optimizer == 'adam':
optimizer = adam(lr=lr)
elif optimizer == 'adadelta':
optimizer = adadelta(lr=lr)
elif optimizer == 'rmsprop':
optimizer = rmsprop(lr=lr)
self.model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
self.model.summary()
fit_summary = self.model.fit(x_train, y_train, epochs=epochs, verbose=0, validation_data=(x_val, y_val), batch_size=20)
if fit_summary.history['acc'][-1] > self.best_accuracy:
# Save the Best model if the accurary score of this model is more than any other model else continue with other hyperparameters
self.best_model = self.model
self.best_accuracy = fit_summary.history['acc'][-1]
self.best_parameters = (layers, activation, optimizer, lr, epochs)
return fit_summary
So the class once all put together looks like :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
class ModelFormer:
def __init__(self):
self.x = []
self.y = []
self.tokenizer = Tokenizer()
self.best_model = Sequential()
self.best_accuracy = 0
self.best_parameters = {}
def fit_data(self, text):
self.original_corpus = text
self.corpus = self.original_corpus.lower().split('\n')
self.tokenizer.fit_on_texts(self.corpus)
self.word_count = len(self.tokenizer.word_index) + 1
input_sequences = []
for line in self.corpus:
tokens = self.tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(tokens)):
n_grams_sequence = tokens[:i+1]
input_sequences.append(n_grams_sequence)
input_sequences = self.pad_input_sequences(input_sequences)
x_data, y_data = input_sequences[:,:-1], input_sequences[:,-1]
y_data = np_utils.to_categorical(y_data, num_classes=self.word_count)
return x_data, y_data
def pad_input_sequences(self,input_sequences):
max_sequence_length = max([len(sentence) for sentence in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_length, padding='pre'))
return input_sequences
def fit(self, x_data, y_data , layers= [( 'LSTM', 150), ('Dropout', 0.2), ('LSTM', 120)], activation='tanh', optimizer='adam', lr=0.01, epochs=20):
self.model = Sequential()
self.x_data = x_data
self.y_data = y_data
# create a train and validation set from the training set
x_train, x_val, y_train, y_val = train_test_split(self.x_data, self.y_data)
self.model.add(Embedding(self.word_count, 10, input_length=len(x_data[0]) ))
count_lstm_retn_flag = [x for x,_ in layers].count('LSTM') - 1
for layer,value in layers:
if layer == 'LSTM':
if count_lstm_retn_flag:
count_lstm_retn_flag -= 1
return_sequences = True
else:
return_sequences = False
self.model.add(LSTM(value, activation=activation, return_sequences=return_sequences))
if layer == 'Dropout':
self.model.add(Dropout(value))
self.model.add(Dense(self.word_count, activation='softmax'))
if optimizer == 'adam':
optimizer = adam(lr=lr)
elif optimizer == 'adadelta':
optimizer = adadelta(lr=lr)
elif optimizer == 'rmsprop':
optimizer = rmsprop(lr=lr)
self.model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
self.model.summary()
fit_summary = self.model.fit(x_train, y_train, epochs=epochs, verbose=1, validation_data=(x_val, y_val), batch_size=20)
if fit_summary.history['acc'][-1] > self.best_accuracy:
self.best_model = self.model
self.best_accuracy = fit_summary.history['acc'][-1]
self.best_parameters = (layers, activation, optimizer, lr, epochs)
return fit_summary
Now lets run the class
1
2
3
4
5
6
7
8
9
10
m = ModelFormer()
X, Y= m.fit_data(text)
x_train , x_test, y_train, y_test = train_test_split(X,Y, test_size=0.3)
hyperparameters = { 'layers': [ [( 'LSTM', 200), ('Dropout', 0.2)], [( 'LSTM', 200), ('Dropout', 0.2), ('LSTM', 400), ('Dropout', 0.2) ]],
'activation': ['tanh'],
'optimizer' : [ ('adam', 0.01 ), ('adam', 0.001 ) , ('adadelta', 1 ), ('rmsprop', 0.1 )],
'epochs' : [50]
}
combinations = list(ParameterGrid(hyperparameters))
Now fitting the data for different hyperparameters and measuring using the m.fit model
1
2
3
4
fit_summary_array = []
for combination in combinations:
print('Current Combination : {}'.format(combination))
m.fit(x_train, y_train, layers=combination['layers'], activation=combination['activation'], optimizer=combination['optimizer'][0], lr=combination['optimizer'][1], epochs=combination['epochs'])
It will run for quite sometime given your GPU but for me the best model and best hyperparameters were
1
2
3
4
5
6
7
8
9
10
11
print('Best Accuracy : {}, with best Parameters : {}'.format(m.best_accuracy*100, m.best_parameters))
## This will give output like =>
#####################################
# Output
#####################################
Best Accuracy : 93.56443026322751, with best Parameters : ([('LSTM', 200), ('Dropout', 0.2)], 'tanh', <keras.optimizers.Adam object at 0x7f69dc151a20>, 0.001, 50)
Now lets some sentences on the testing data we had
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# Generate Sentences :
def generate_n_sentences(n=5):
final_sentences = []
for _ in range(n):
prediction = x_test[np.random.randint(len(x_test))]
prediction = np.delete(prediction, 0)
first_prediction = m.best_model.predict_classes([x_test[0].reshape(1,54)])
prediction = np.append(prediction,first_prediction)
for _ in range(5):
next_prediction = m.best_model.predict_classes(prediction.reshape(1,54))
prediction = np.delete(prediction, 0)
prediction = np.append(prediction,next_prediction)
output_word = ""
for i in prediction:
if i:
for word,index in m.tokenizer.word_index.items():
if index == i:
output_word += word + ' '
break
final_sentences.append(output_word)
return final_sentences
generate_n_sentences(10)
Output Came like:
1
2
3
4
5
6
7
8
9
10
['we negotiated a ceasefire in parts our terrible amp russia the russians ',
'should federal election commission and or fcc look into this there must be collusion with the democrats and of course russia such one sided media coverage most of it our fake news media collusion so ',
'slippery james comey the worst fbi director in history was not our scheme of the democrats lead ',
'“i have seen all of the russian ads and i can say very definitively that swaying the election was not the main goal ”rob goldmanvice president of facebook our p more leakin’ i nice ',
'not associated our vindicates “trump” on russia and ',
'if it was the goal of russia to create discord our investigation to into the details ',
'why did the obama administration start an investigation into the trump campaign with zero proof of wrongdoing our country of this fbi against ',
'the mainstream media has refused to cover the fact that the head of the very important senate intelligence committee after two years of intensive study and access to our north korea north korea powerhouse ',
'remember it was our implanted a must gun tying ',
'“no matter your ideologies or your loyalties this is a good day for america no our conspired to his have and ']
Which does sound like Trump :D.
Hope you enjoy this and if any doubts ask me in the comment section. You can generate different text just change the corpus and data read method.