
(Migrated from old blog)
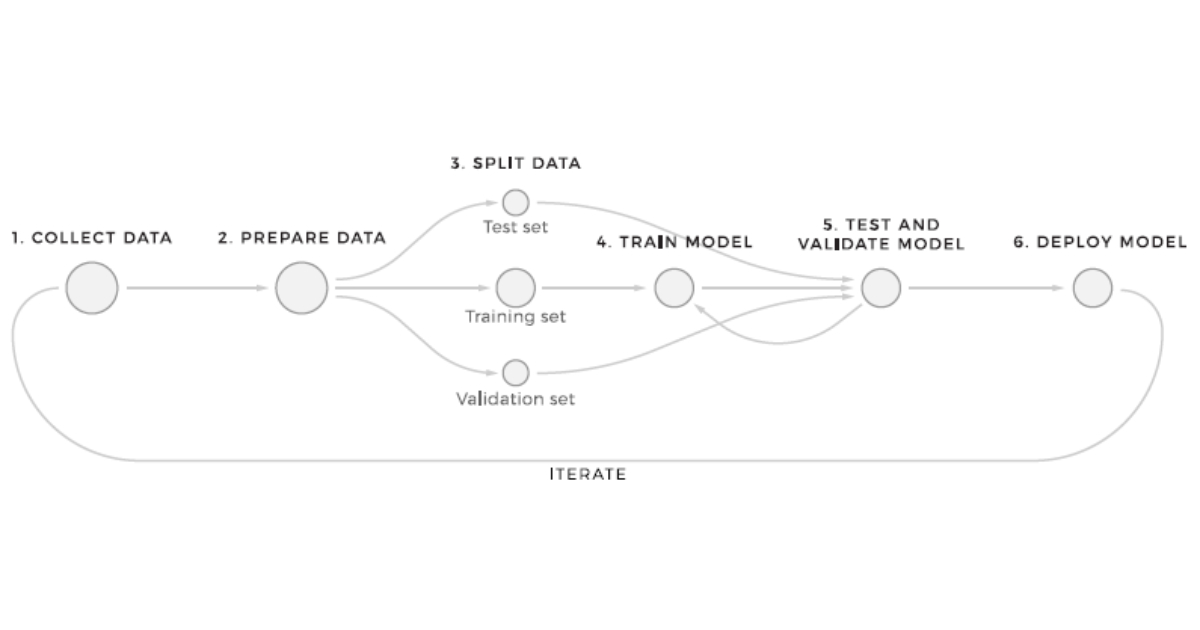
So we want to train our machine learning algorithm or a deep learning model, what we generally do (old school approach) is to split the data set into 70-30 percent and call 70 percent as a training set and the 30 percent as the testing set. But here is a catch, we can implement better ways to increase the accuracy and with the help of that tune the hyperparameters and some optimization techniques. Sounds Cool?
So in the starting phases and even now, what the general approach was to use train test split and split the data into 70-30 %, 80-20 %, which the larger chunk was the train set and the smaller chunk was the test set.
But the downside of this is that, there is no way to tune the hyperparameters and if you do it on the testing set you are kind of fitting the testing set into your model which is never a good idea as you want the testing set to show the real statistics of your model.
So , the new approach now a days is that, We split the dataset into three parts, that is Train Set on which we train the data a Dev set one which we check the accuracy of our model and tune the hyperparameters for multiple iterations until we are confident that this model is ready to be tested on the test set.
 Train, dev/eval, test sets
Train, dev/eval, test sets
So, the train set can come from anywhere may it be webscrapping or any other feed but the main optimizating point that we have to take care of it that the ideally the dev set and the test set should come from the same distribution.
Sometimes its okay to not to have a test set but it is good if you have it otherwise you might overtune the parameters for dev set ( or testing set in this scenario). The size of the dev and test should not be huge, I can be divided like 90% Train, 5% Dev and 5% Test. Sometimes if you data is huge. Even 99% Train and 0.5% Dev and 0.5% Test is sufficient for the model to perform well.
Bias and Variance
In this context, if your dev set has high errors but the test set is good, that means that the model has high bias but low variance this means that the model is under fit. If the dev set has low errors but the test set has high errors that means that it has high variance and low bias. But the good test set it what that does not have a high variance and not a high bias.
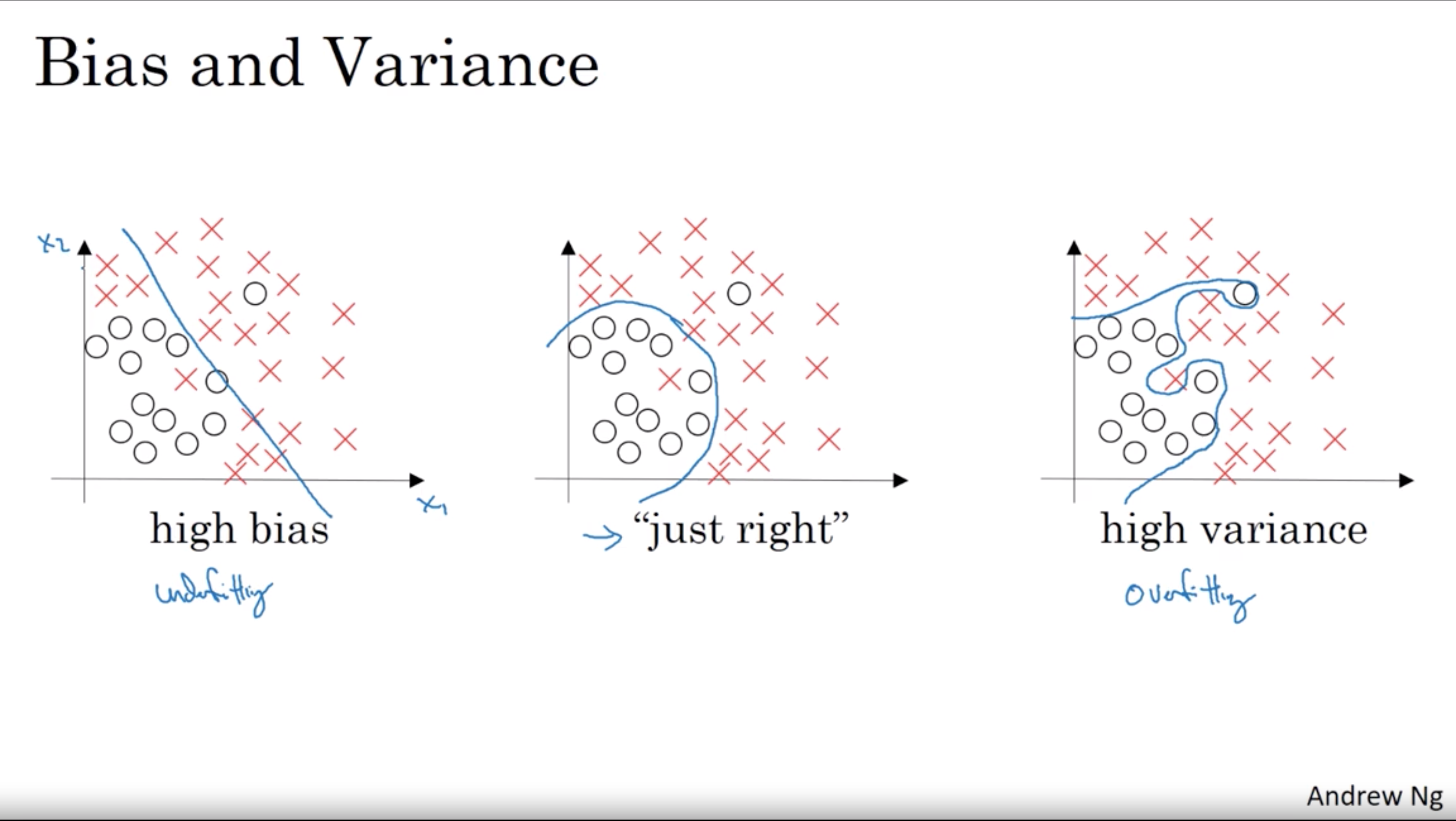 Bais-variances tradeoff in machine learning models ~ by Andrew Ng
Bais-variances tradeoff in machine learning models ~ by Andrew Ng
Life Hack Flow Chart for Neural Networks
I too am new to this but it sounds pretty amazing. This flow chart should generally fix most of the problems.
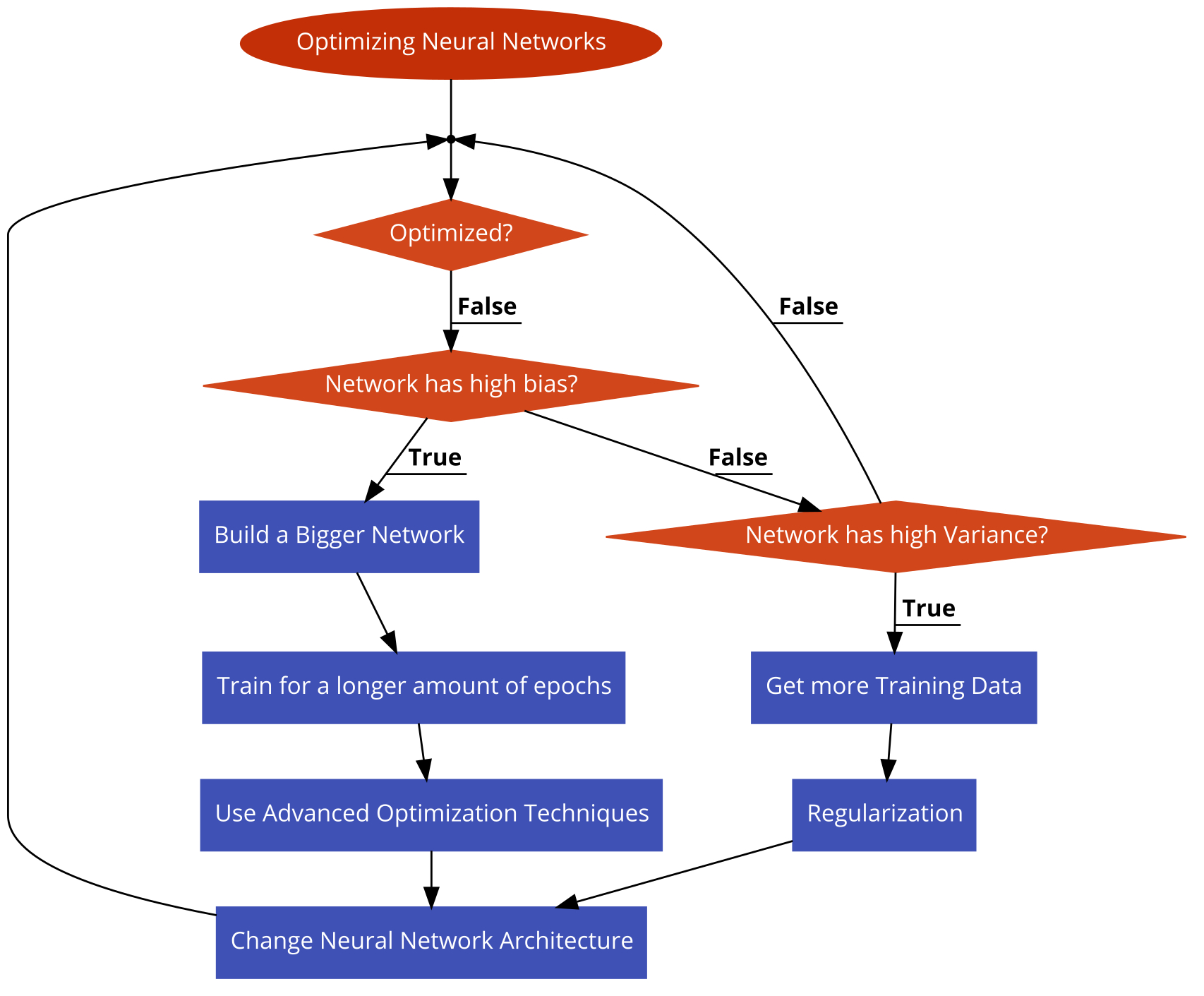 Optimizing neural network
Optimizing neural network